개인공부/Machine Learning
[Dacon] 고객 대출등급 분류 AI 해커톤 _ 우수코드리뷰(1.BASELINE)
알파카유진정
2024. 3. 2. 10:38
제공 데이터셋
: TEST.csv
: TRAIN.csv
: SAMPLE_SUBMISSION.csv
BASE LINE CODE로 제시된 코드이다.
우선, Random Seed를 고정한다.이 뒤로 데이터를 휘저을 때 자꾸 휘저을까봐 한번 휘저어서 저장해버리는 느낌으로 이해하면 된다.
import numpy as np
import random
import os
def seed_everything(seed):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
seed_everything(42)
import pandas as pd
train_df = pd.read_csv('/content/train.csv')
test_df = pd.read_csv('/content/test.csv')
display(train_df.head(3))
display(test_df.head(3))- print() 함수는 데이터프레임을 텍스트 형식으로 출력합니다. 각 행과 열이 텍스트로 나타나며, 형식이나 구조가 유지되지 않을 수 있습니다.
- display() 함수는 데이터프레임을 보다 시각적으로 표현합니다. 이는 주피터 노트북 등에서 더 보기 편하고, 테이블 형태로 깔끔하게 표시됩니다. 또한, 데이터프레임의 형식과 구조가 유지되어 보다 명확하게 데이터를 이해할 수 있습니다.
EDA:범주형 데이터를 해석한다.
# 시각화 패키지 불러오기
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
# 한글 폰트 설정하기
fe = fm.FontEntry(fname = 'MaruBuri-Regular.otf', name = 'MaruBuri')
fm.fontManager.ttflist.insert(0, fe)
plt.rc('font', family='MaruBuri')
fig, axes = plt.subplots(2, 2, figsize=(25,10)) # 2x2 형식으로 4개 그래프 동시에 표시
sns.countplot(x = train_df['대출기간'], ax=axes[0][0]).set_title('대출기간')
sns.countplot(x = train_df['근로기간'], ax=axes[0][1]).set_title('근로기간')
sns.countplot(x = train_df['주택소유상태'], ax=axes[1][0]).set_title('주택소유상태')
sns.countplot(x = train_df['대출목적'], ax=axes[1][1]).set_title('대출목적')
plt.show()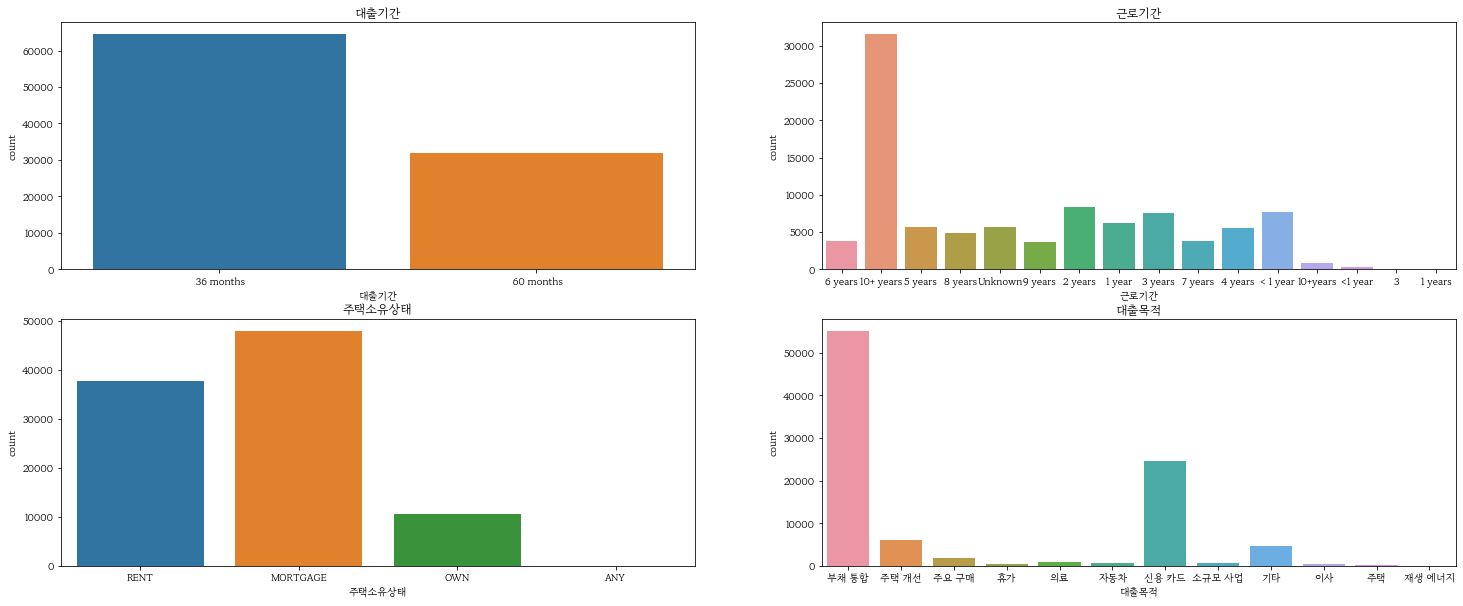
데이터전처리 과정이다.
여기서는 근로기간과 대출 등급을 사용한다.
train_x = train_df.drop(columns=['ID', '근로기간', '대출등급'])
train_y = train_df['대출등급']
test_x = test_df.drop(columns=['ID', '근로기간'])
LableIncoder로 범주형 수치화를 진행한다.
from sklearn.preprocessing import LabelEncoder
categorical_features = ['대출기간', '주택소유상태', '대출목적']
for i in categorical_features:
le = LabelEncoder()
le=le.fit(train_x[i])
train_x[i]=le.transform(train_x[i])
for case in np.unique(test_x[i]):
if case not in le.classes_:
le.classes_ = np.append(le.classes_, case)
test_x[i]=le.transform(test_x[i])
display(train_x.head(3))
display(test_x.head(3))- for 루프에서 각각의 범주형 변수에 대해 LabelEncoder를 만들고 훈련 데이터에 대해 .fit() 메서드를 사용하여 해당 변수를 학습합니다.
- 그런 다음 train_x와 test_x의 각 범주값을 숫자로 변환하기 위해 .transform() 메서드를 사용합니다.
- 이때 test_x에 대해서는 학습 과정에서 등장하지 않았던 새로운 범주값이 있을 수 있으므로, 이를 고려하여 LabelEncoder의 classes_ 속성을 업데이트합니다. 이를 통해 테스트 데이터에서 새로운 범주값이 발견되면 LabelEncoder가 이를 처리할 수 있습니다
- Labelencoder의 역할
- 각 범주 값을 고유한 정수로 매핑: fit() 메서드를 사용하여 범주형 변수의 각 값에 대해 정수로 매핑합니다. 예를 들어, ['고양이', '개', '쥐']와 같은 범주형 변수가 있다면, 이를 각각 0, 1, 2와 같은 정수로 매핑합니다.
- 범주 값의 정수 인코딩: transform() 메서드를 사용하여 학습된 매핑 정보를 바탕으로 범주형 변수를 정수형으로 인코딩합니다. 예를 들어, '개'는 1로, '고양이'는 0으로 변환됩니다.
- 새로운 범주 값 처리: fit() 메서드로 학습된 범주 값 이외의 새로운 값이 테스트 데이터에 나타날 경우, 이를 무시하거나 특정 값을 할당합니다. 이를 위해 LabelEncoder는 classes_ 속성을 사용합니다.
데이터 전처리 기본 (1) - data encoding
데이터 전처리(Data Preprocessing) ML AL이 data에 기반하므로, 데이터를 어떻게 처리하느냐에 따라 결과가 달라질 수 있음. sklearn의 ML AL을 적용하기 전 반드시 해야할 전처리 결손값 처리. NaN, Null값은
pycode.tistory.com
참고~
자 이제 모델을 학습시킵니다~!
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
model.fit(train_x, train_y)사이킷런(Scikit-learn)의 RandomForestClassifier 클래스를 사용하는데!
랜덤 포레스트는 앙상블 학습 기법 중 하나로, 여러 개의 결정 트리를 사용하여 분류를 수행한다.
각 결정 트리는 무작위로 선택한 데이터로 학습하며, 그 결과를 종합하여 최종 예측을 수행한다.
자 여기서 앙상블 기법이라는 게 뭘까?
- 앙상블(Ensemble) 기법은 여러 개의 간단한 모델을 결합하여 하나의 강력한 모델을 구성하는 기법이다.
- 앙상블은 주로 분류(Classification)와 회귀(Regression) 문제에서 사용되며, 그 중에서도 분류 문제에서 두드러지게 성과를 내는 경우가 많음.
- https://realalpaca01.tistory.com/18
- Bagging 배깅
- 배깅은 동일한 기본 모델을 사용하되, 학습 데이터를 무작위로 선택하여 복수의 모델을 병렬로 학습시키는 방법, 이때 각 모델은 독립적으로 학습되며, 예측을 수행한 후 결과를 평균화하거나 다수결 등의 방법을 사용하여 최종 예측을 결정 EX ) 랜덤포레스트
- Boosting 부스팅
- 부스팅은 약한 모델을 순차적으로 학습하여 강력한 모델을 만드는 방법, 각 모델은 이전 모델의 예측 오차를 보정하도록 학습한다. EX ) 에이다부스트(AdaBoost), 그래디언트 부스트(Gradient Boosting), XGBoost, LightGBM 등이 있습니다
- Bagging 배깅
- https://realalpaca01.tistory.com/18
자 이제 학슴을 했을테니 예측을 결고를 볼까용!
pred = model.predict(test_x)
sample_submission = pd.read_csv(''/content/sample_submission.csv', encoding='UTF-8')
sample_submission['대출등급'] = pred
sample_submission해서 ~ 예측 결과 보면 되는데 이건 그~ BASELINE이라
다음 게시물에서 다른 함수 쓰고 예측 결과 보여줄게용~